local의 csv 파일 linux 환경에 옮기기
scp C:\Users\Playdata\Downloads\휴게음식점_인허가정보.csv root@192.168.111.100:/root/hadoop-3.3.6colab에서 전처리 후 일반음식점_인허가정보, 휴게음식점_인허가정보 옮김
Hadoop에 csv 파일 저장
[root@localhost ~]# hadoop fs -mkdir -p /user/root/coffee/normal
[root@localhost ~]# hadoop fs -mkdir -p /user/root/coffee/cafe
[root@localhost ~]# hadoop fs -put 일반음식점_인허가정보.csv /user/root/coffee/normal
[root@localhost ~]# hadoop fs -put 휴게음식점_인허가정보.csv /user/root/coffee/cafeHive에 테이블 생성 - 일반음식점 table
hive> create external table coffee.normal
> (
> statusCode INT,
> status STRING,
> upjong STRING,
> openYear STRING,
> openMonth STRING,
> closedYear STRING,
> closedMonth STRING,
> gu STRING
> )
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ','
> LINES TERMINATED BY '\n'
> STORED AS textfile
> LOCATION '/user/root/coffee/normal';년도별 영업 시작 지점 수 추출
select normal.openYear, count(*) from normal where normal.statuscode==1 and normal.openYear >= 2021 group by normal.openYear;
년도별 폐업 지점 수 추출
hive> select normal.closedYear, count(*) from normal where normal.statuscode==2 and normal.closedYear >= 2021 group by normal.closedYear;table 생성
hive> create external table normalYear
> (
> year STRING,
> opened INT,
> closed INT
> )
> ;insert into 사용해서 위의 데이터 저장
2021~2023년 월별 영업,폐업 지점 수
hive> select normal.openYear, normal.openMonth, count(*)
from normal where normal.openYear >= '2021' and normal.openYear <= '2023'
group by normal.openYear, normal.openMonth;위 쿼리는 영업 지점 수를 select하는 쿼리
폐업 지점 수 select하는 쿼리도 생성함
영업, 폐업 table 생성
create external table normalopen
(
year INT,
month INT,
open STRING
);
create external table normalclose
(
year INT,
month INT,
close STRING
);insert into
insert into table normalopen
select normal.openYear, normal.openMonth, count(*)
from normal where normal.openYear >= '2021' and normal.openYear <= '2023'
group by normal.openYear, normal.openMonth;normalclosed table도 비슷하게 해준다
join
join 하기 전에 normalfinal 테이블의 스키마도 미리 생성해두어야 한다. (여기선 생략함)
hive> insert into table normalfinal
> select o.year, o.month, o.open, c.close
> from normalopen o
> join normalclose c
> on o.year = c.year and o.month = c.month;sqoop을 활용하여 hive 테이블 mysql로 추출
hadoop fs 의 /user/root/coffee/output 경로에 normalfinal 테이블을 저장
hive> insert overwrite directory '/user/root/coffee/output' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' SELECT * FROM normalfinal;hadoopguide 유저의 mysql : hadoopguide 데이터베이스 아래 normal 테이블을 생성해두었다
생성한 테이블의 schema는 이러하다. hive에서 추출한 normalfinal 테이블과 같은 구조로 생성한다.
CREATE TABLE normal (
year INT,
month INT,
open VARCHAR(255),
close VARCHAR(255)
);sqoop export
- import: DB -> HDFS 로 데이터를 가져온다.
- export: HDFS -> DB 로 데이터를 가져온다.
[root@localhost sqoop]# sqoop export --connect jdbc:mysql://localhost/hadoopguide --username hadoopguide
--password [비밀번호]
--table normal
--export-dir /user/root/coffee/output
--input-fields-terminated-by ','sqoop을 이용해서 export-dir에 있는 정보를 mysqld의 hadoopguide database의 normal table에 저장한다.
<저장된 결과 확인>
sqoop import
mysql에 저장된 table을 hdfs로 다시 꺼내서 확인해봤다. (그냥)
[root@localhost sqoop]# sqoop import --connect jdbc:mysql://localhost/hadoopguide --table normal
--target-dir /user/root/coffeeoutput
--username hadoopguide --P -m 1[root@localhost sqoop]# hadoop fs -ls /user/root/coffeeoutput
Found 2 items
-rw-r--r-- 1 root supergroup 0 2024-03-15 16:20 /user/root/coffeeoutput/_SUCCESS
-rw-r--r-- 1 root supergroup 606 2024-03-15 16:20 /user/root/coffeeoutput/part-m-00000
[root@localhost sqoop]# hadoop fs -cat /user/root/coffeeoutput/part-m-00000
sqoop으로 hdfs에서 mysql로 export한 테이블을 python과 연결해서 시각화 하려는 것이 목표이다.
대충 그려본 아키텍쳐
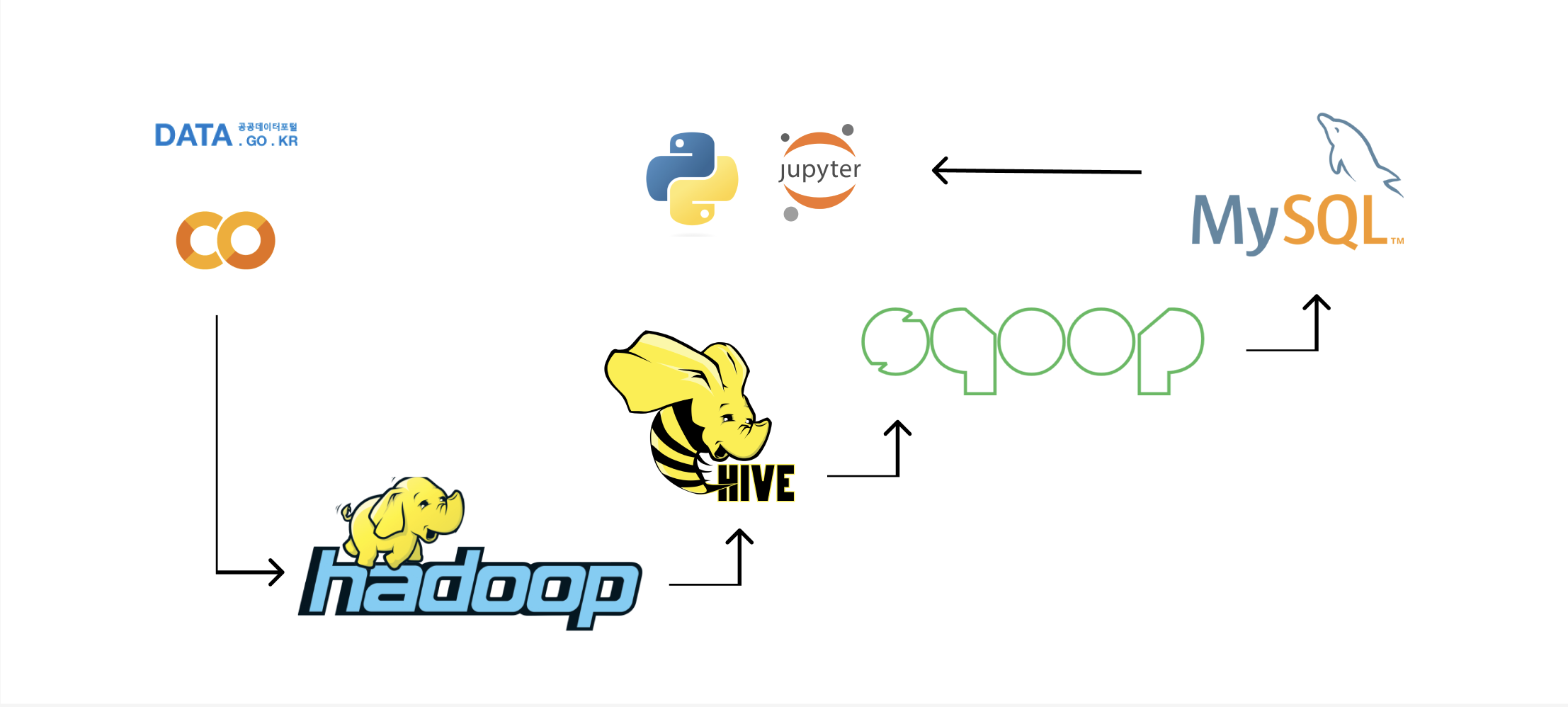
'PLAYDATA' 카테고리의 다른 글
| flask 서버 구조 (0) | 2024.05.19 |
|---|---|
| [플레이데이터 데이터 엔지니어링 30기] 3월 3주차 회고 (0) | 2024.03.19 |
| [플레이데이터 데이터 엔지니어링 30기] 3월 2주차 회고 (0) | 2024.03.12 |
| [PLAYDATA 데이터 엔지니어링] 3월 1주차 회고 (0) | 2024.03.05 |
| 2월 3주차 회고 (0) | 2024.02.20 |