map, reduce 활용 예제
wordcount
word_counts = text.flatMap(lambda line:line.split()).map(lambda word : (word, 1)).reduceByKey(lambda x,y : x+y)
word_counts.collect()
모두 2 곱하기
numbers = spark.sparkContext.parallelize([1,2,3,4,5,6,7,8,9])
numbers.map(lambda x : x*2).collect()
짝수만 필터링
numbers.filter(lambda x : x%2 == 0).collect()
모든 요소의 합 구하기
numbers.reduce(lambda x,y : x+y)각 요소의 길이
# 각 요소의 길이
text = spark.sparkContext.parallelize(["abc","aaa","bbbbbbbbbbbbbbb"])
text.map(lambda x : len(x)).collect()정렬
text.sortBy(lambda x : x).collect()union
# RDD 두개 분할해서 합치기
rdd1 = spark.sparkContext.parallelize([1,10,20])
rdd2 = spark.sparkContext.parallelize([10,100,200])
merged_rdd = rdd1.union(rdd2)
merged_rdd.collect()
lower, upper 활용
myCollection = "Spark The Definitive Guide: Big Data Processing Made Simple".split()
words = spark.sparkContext.parallelize(myCollection,2)
words.take(2)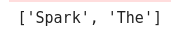
words.map(lambda w : (w.lower(),1)).collect()
keyword = words.keyBy(lambda w : w.lower()[0])
keyword.mapValues(lambda w: w.upper()).collect()
keyword.flatMapValues(lambda w : w.upper()).collect()
keyword.keys().collect() # key
keyword.values().collect() # value각 단어에서 소문자로 변환된 문자들을 추출
중복된 문자를 제거
각 문자에서 무작위로 생성된 값을 가지는 샘플을 생성
각 단어의 첫 문자를 키로 하고 단어를 값으로 하는 키-값 쌍을 생성
sampleByKey() 함수를 사용해 각 키에 대한 샘플을 추출
# 각 단어에서 소문자로 변환된 문자들을 추출
words.map(lambda x : x.lower())
# 중복된 문자를 제거
distinctChar = words.flatMap(lambda x : x.lower()).distinct().collect()
# 각 문자에서 무작위로 생성된 값을 가지는 샘플을 생성
import random
sampleMap = dict(map(lambda c : (c, random.random()), distinctChar))
words.map(lambda w : (w.lower()[0], w)).sampleByKey(True, sampleMap,6).collect()
# words 단어리스트를 소문자로 변환한 후 각 문자를 추출
chars = words.flatMap(lambda w:w.lower())
chars.take(2)
# 각 단어의 첫 문자를 키로 하고 단어를 값으로 하는 키-값 쌍을 생성
dic_chars = chars.map(lambda w:(w,1))
dic_chars.take(2)
# dic_chars를 이용해서 각 문자의 출현 빈도를 계산
dic_chars.reduceByKey(lambda x,y : x+y).collect()
# sampleByKey() 함수를 사용해 각 키에 대한 샘플을 추출def maxFunc(left, right):
return max(left, right)
def addFunc(left, right):
return left + right;
# nums에서 최댓값
max_value = nums.reduce(maxFunc)
print(f"max_value : {max_value}")
# nums 모든 값의 합 구하기
total_sum = nums.reduce(addFunc)
print(f"total_sum : {total_sum}")from functools import reduce
dic_chars.groupByKey().map(lambda row : (row[0], reduce(addFunc, row[1]))).collect()
'Data Engineering > Spark' 카테고리의 다른 글
| [Spark] Pipeline, Logistic Regression (0) | 2024.03.26 |
|---|---|
| [Spark] csv 파일 로드, 전처리, parquet 저장 (0) | 2024.03.25 |
| [Spark] csv 파일 로드하고 RDD로 처리하기 (0) | 2024.03.25 |
| [Spark] Spark RDD - parallelize, collect, map, flatMap, filter, sortBy, mapPartitions, glom (0) | 2024.03.25 |
| [Spark] MySQL 연결 (0) | 2024.03.22 |



