RDD 객체 생성
# DataFrame -> RDD
spark.range(100).rdd
# 0~9 꺄지 담긴 rdd 객체 생성
spark.range(10).toDF("id").rdd.map(lambda row: row[0])
# RDD를 다시 dataframe으로 변환
spark.range(10).rdd.toDF()rdd 호출 후 toDF는 일반적이지 않음
myCollection = "Spark The Definitive Guide: Big Data Processing Made Simple".split()
myCollection
parallelize
# 2개의 파티션으로 나눔
words = spark.sparkContext.parallelize(myCollection,2)map
- 하나의 인자를 받는 함수 자체가 map의 인자로 들어감
- 이 함수를 이용해 rdd의 모든 요소에 적용한 뒤 새로운 RDD 리턴
# 각 문장의 길이를 구한다
w_length = words.map(lambda w : len(w))
# rdd 객체를 다시 모은다
w_length.collect()
이름 지정해주기
words.setName("myWords")
words.name()filter
# RDD Filtering
def startsWithS(data):
return data.startswith("S")
words.filter(lambda w : startsWithS(w)).collect()
words2 = words.map(lambda word: (word,word[0],word.startswith("S")))
words2word, word[0] (word의 첫번째), word가 "S"로 시작하는지 여부 를 저장
words2는 RDD 객체
# 첫 5개의 결과를 가져옴
words2.filter(lambda record : record[2]).take(5)
True인 데이터만 filtering
flatMap
- map()과 마찬가지로, 하나의 인자를 받는 함수가 flatMap의 인자로 들어감
- map()과 차이점은 각 함수의 인자가 반환하는 값의 타입이 다름
words.flatMap(lambda word : list(word)).take(5)
정렬 sortBy
words.sortBy(lambda word: len(word)* -1).take(2)-1 : 단어의 길이를 계산해서 음수로 반환 -> 내림차순으로 정렬
randomSplit
split_50 = words.randomSplit([0.5,0.5]) # rdd를 50%씩 두 부분으로 나눔reduce
1부터 20까지 더하기
# reduce 1 ~ 20 total summary
spark.sparkContext.parallelize(range(1,21)).reduce(lambda x,y : x+y)# 두 개의 단어 중에서 길이가 긴 단어를 선택하는 reducer
def wordLengthReducer(leftWord, rightWord):
return leftWord if len(leftWord) > len(rightWord) else rightWord
words.reduce(wordLengthReducer)-> words에서 가장 긴 문자열이 리턴됨 : 'Processing'
getNumPartitions
words.getNumPartitions()mapPartitions
words.mapPartitions(lambda part : [1]).sum()# 각 파티션의 인덱스와 해당 파티션에 속한 각 요소를 사용 -> 새로운 값 생성
def indexedFunc(partitionIndex, withinPartIterator):
return [ f"partition:{partitionIndex} => {x}" for x in withinPartIterator]
words.mapPartitionsWithIndex(indexedFunc).collect()
0번 파티션과 1번 파티션을 볼 수 있음
glom
RDD 요소를 Partition별로 그룹화, 리스트로 반환
spark.sparkContext.parallelize(["Hello","World"],2).glom().collect()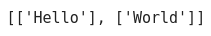
'Data Engineering > Spark' 카테고리의 다른 글
| [Spark] map, reduce 활용 (0) | 2024.03.25 |
|---|---|
| [Spark] csv 파일 로드하고 RDD로 처리하기 (0) | 2024.03.25 |
| [Spark] MySQL 연결 (0) | 2024.03.22 |
| [Spark] join 연산, csv, json, Parquet, ORC (0) | 2024.03.22 |
| [Spark] 집계연산, corr, Window (0) | 2024.03.21 |



