날짜
current_date, current_timestamp
# 날짜
from pyspark.sql.functions import current_date, current_timestamp
datedf = spark.range(10).withColumn('today',current_date())\
.withColumn("now",current_timestamp())
datedf.show(truncate=False)
datedf.createOrReplaceTempView('datedf')
date_add, date_sub
from pyspark.sql.functions import date_add, date_sub
datedf.select(date_sub('today',5), date_add('today',5)).show(1)date_sub('today',5) : 오늘 날짜에서 5일 뺌
date_add('today',5) : 오늘 날짜에서 5일 더함

datediff
from pyspark.sql.functions import datediff, months_between, to_date
# 현재 날짜에서 7일만큼 뺌
datedf.withColumn('week_ago',date_sub('today',7))\
.select(datediff('week_ago','today')).show(1)
months_between, to_date
datedf.select(to_date(lit('2024-03-21')).alias('start'),
to_date(lit('2024-05-08')).alias('end'))\
.select(months_between('start','end')).show(1)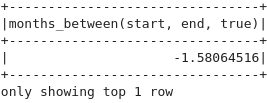
from pyspark.sql.functions import to_date, lit
spark.range(10).withColumn('date',lit('2024-05-02')).select('date',to_date('date')).show(1)
date는 문자열, to_date(date)는 date type
# dateformat 적용시켜서 바꾸기
dateformat = 'yyyy-dd-MM'
spark.range(1).select(to_date(lit('2024-05-02'), dateformat)).show()
coalesce
data = [
(None,2),
(1,None),
(1,2),
(None,None)
]
example_df = spark.createDataFrame(data,['a','b'])
example_df.show()
coalesce 결과
example_df.select(coalesce('a','b')).show()
isNull()
example_df.filter(col("a").isNull() | col("b").isNull()).show()
drop()
example_df.na.drop('all',subset=['a']).show()
fill()
fill_cols_vals = {'a':100,'b':5}
example_df.na.fill(fill_cols_vals).show()
struct
# 컬럼끼리 묶기 - 복합컬럼
from pyspark.sql.functions import struct
df.select(struct('Description','InvoiceNo').alias('complete')).show(truncate=False)split
from pyspark.sql.functions import split
# 공백을 기준으로 split
df.select(split("Description"," ")).show(2,False)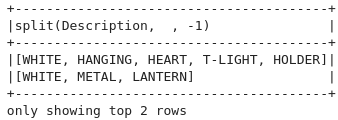
df.select(split("Description"," ").alias("array_col"))\
.selectExpr("array_col[0]").show(2)
size
from pyspark.sql.functions import size
df.select(size(split("Description"," "))).show(2)
explode
새로운 행으로 확장
# 새로운 행으로 확장
from pyspark.sql.functions import explode
df.withColumn("splitted",split("Description"," "))\
.withColumn('exploded',explode('splitted'))\
.select('Description','splitted','exploded').show(2,False)원본 데이터는 Description, splitted 한줄씩 나오는데 exploded 하면 여러줄 생김
원본 데이터(Description, splitted)

exploded 결과

create_map
from pyspark.sql.functions import create_map
df.select(create_map('Description','InvoiceNo').alias('complex_map')).show(2,False)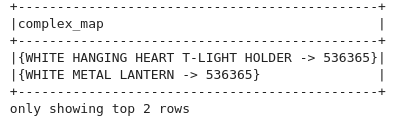
get_json_object, json_tuple
# JSON TYPE DATAFRAME
json_df = spark.range(1).selectExpr("""
'{"myJSONKey":{"myJSONValue" : [1,2,3]}}' as jsonString
""")
from pyspark.sql.functions import get_json_object, json_tuple
json_df.select(
get_json_object('jsonString',"$.myJSONKey.myJSONValue[1]").alias('column'),
json_tuple('jsonString','myJSONKey')
).show(1,False)
json_tuple : 해당되는 value의 값 반환
to_json
from pyspark.sql.functions import to_json
df.selectExpr("(InvoiceNo, Description) as myStruct").show(2,truncate=False)
df.selectExpr("(InvoiceNo, Description) as myStruct")
.select(to_json('myStruct'))
.show(2,truncate=False)
'Data Engineering > Spark' 카테고리의 다른 글
| [Spark] join 연산, csv, json, Parquet, ORC (0) | 2024.03.22 |
|---|---|
| [Spark] 집계연산, corr, Window (0) | 2024.03.21 |
| [Spark] 기본 연산 - 2 (0) | 2024.03.21 |
| [Spark] 기본 연산 (0) | 2024.03.21 |
| [Spark] Jupyterlab, Spark를 이용한 데이터 전처리 (0) | 2024.03.20 |



