filepath = 'bydata/by-day/2010-12-01.csv'
df = spark.read.format("csv").option("header","true").option("inferSchema","true").load(filepath)df.createOrReplaceTempView("dfTable")
from pyspark.sql.functions import lit
df.select(lit(5), lit('five'), lit(2.0)).show(2)
예제1
InvoiceNo != 536365 인 컬럼 InvoiceNo, Description 5개만 출력하기
from pyspark.sql.functions import col
df.where(col("InvoiceNo") != 536365).select("InvoiceNo","Description").show(5, False)spark sql 사용하기
spark.sql("""
select InvoiceNo,Description from dfTable where InvoiceNo != 536365 limit 5
""").show(truncate = False)
truncate = False 옵션 사용하면 안잘리고 보임!
예제2
1.가격이 600 이상
2.Description POSTAGE 문자열이 포함
1,2 조건 중 하나라도 만족 시 StockCode의 값 중에 DOT 인 행을 선택
내 풀이
df.where((col('UnitPrice') >= 600) | (col('Description').contains('POSTAGE')))\
.where(col('StockCode') == 'DOT').show()
다른 풀이
from pyspark.sql.functions import instr
dotcondition = col('StockCode') == 'DOT'
pricecondition = col('UnitPrice') >= 600
descondition = instr(col('Description'),'POSTAGE') >= 1
df.where(dotcondition).where(pricecondition | descondition).show()
SQL을 활용한 풀이
내 풀이
spark.sql("""
select * from dfTable
where StockCode == 'DOT'
and (UnitPrice >= 600 or Description LIKE '%POSTAGE%')
""").show()다른 풀이
spark.sql("""
select * from dfTable
where StockCode == 'DOT'
and (UnitPrice >= 600 or INSTR(Description,'POSTAGE') >= 1)
""").show()INSTR 함수 : 문자열에서 문자를 찾으면 문자의 시작 위치를 반환한다. 문자를 찾지 못하면 "0"을 반환한다.
# 조건을 만들고 조건에 맞는 새로운 데이터를 새로운 컬럼에 넣어서 추가
df.withColumn('isExpensive',dotcondition & (pricecondition | descondition)).show()# isExpensive == True 인 항목중에 UnitPrice, isExpensive 출력
df.withColumn('isExpensive',dotcondition & (pricecondition | descondition))\
.where(col('isExpensive')=='true').select('UnitPrice','isExpensive').show()
where에 col 안쓰고 해도 됨
만약에 새롭게 dataframe 생성하고 이어서 쓰고싶으면
# 새로운 DataFrame 생성
new_df = df.withColumn('isExpensive', dotcondition & (pricecondition | descondition))
# isExpensive가 True인 행 선택 후 UnitPrice와 isExpensive 컬럼 출력
result_df = new_df.where(col('isExpensive') == True).select('UnitPrice', 'isExpensive')
# 결과 출력
result_df.show()# (수량*가격) **2 +5 --> 새로운 컬럼에 대입
from pyspark.sql.functions import expr, pow
new_col = pow(col('Quantity')*col('UnitPrice'),2)+5
df.select(expr('CustomerId'),new_col.alias("realQuantity")).show(2)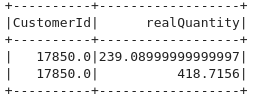
반올림, 내림
round : 반올림
bround : 내림
from pyspark.sql.functions import round, bround, lit
df.select(round(lit(2.5)), bround(lit(2.5))).show()
describe : 통계값 구하기
df.select('UnitPrice').describe().show()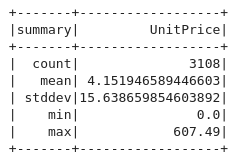
표준편차, 사분위수 approxQuantile
from pyspark.sql.functions import count,mean,stddev_pop,min,max
# stddev_pop : 모집단의 표준편차 - 모든 개체에 대한 표준편차 즉, 실제 표준편차를 계산
# stddev : 표본의 표준편차
colname = 'Quantity'
quantileProbs = [0.5] # 사분위수 - 중위수
realError = 0.05 # 신뢰도
df.stat.approxQuantile(colname, quantileProbs, realError)crosstab
빈도를 나타냄
df.stat.crosstab("StockCode","Quantity").show(2)# df 데이터 중에서 10개만 추출한 df : df_stockcode_quantity_top10
df_stockcode_quantity_top10 = df.limit(10)
df_stockcode_quantity_top10.stat.crosstab("StockCode","Quantity").show()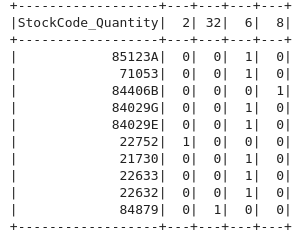
freqItems
df_stockcode_quantity_top10.stat.freqItems(["StockCode","Quantity"]).show()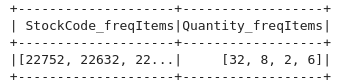
순차적으로 부여
from pyspark.sql.functions import monotonically_increasing_id
df.select(monotonically_increasing_id()).show()
initcap
첫글자 대문자로 바꿔주기
from pyspark.sql.functions import initcap
df.select(initcap("Description")).show()lower, upper
from pyspark.sql.functions import lower, upper
df.select(col('Description'),lower('Description'),upper('Description')).show(2)
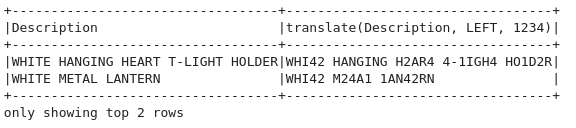
translate
from pyspark.sql.functions import translate
df.select('Description',translate("Description",'LEFT','1234')).show(2, truncate=False)LEFT를 1234로 바꿈
정규표현식
# 정규표현식
# Description 중에서 색상과 관련된 단어가 있는지 조사
from pyspark.sql.functions import regexp_extract
extract_str = "(BLACK|WHITE|RED|GREEN|BLUE)"
df.select(regexp_extract('Description',extract_str,1).alias('color'),
'Description'
).show(5)
# instr 함수를 이용해서 Description 중에서 특정 문자열이 포함되어 있는지 여부를 확인하고 새로운 열을 추가
bcondition = instr(col('Description'),'BLACK') >= 1
wcondition = instr(col('Description'),'WHITE') >= 1
df.withColumn('hasColorBW',bcondition|wcondition).show(10)from pyspark.sql.functions import expr,locate
simpleColors = ['black','white','red','green','blue']
def color_location(column, color_string):
return locate(color_string.upper(),column.cast('boolean').alias('is_'+color_string))
selected_columns = [ color_location(df.Description, c) for c in simpleColors]
selected_columns.append(expr('*'))
df.select(selected_columns).show()-> 고치기
'Data Engineering > Spark' 카테고리의 다른 글
| [Spark] 집계연산, corr, Window (0) | 2024.03.21 |
|---|---|
| [Spark] 날짜 연산, 기본 연산 -3 (1) | 2024.03.21 |
| [Spark] 기본 연산 (0) | 2024.03.21 |
| [Spark] Jupyterlab, Spark를 이용한 데이터 전처리 (0) | 2024.03.20 |
| [Spark] Zeppelin 설치하기 (1) | 2024.03.20 |



