https://www.data.go.kr/data/15061057/fileData.do
주택도시보증공사_전국 신규 민간아파트 분양가격 동향_20230630
주택분양보증을 받아 분양한 전체 민간 신규아파트 분양가격 동향으로 지역별, 면적별 분양가격 등의 자료를 제공합니다.<br/>해당 데이터는 주택도시보증공사 홈페이지 및 통계청 KOSIS에서도
www.data.go.kr
한글 깨짐 인코딩
[root@localhost ~]# iconv -c -f euc-kr -t utf-8 주택도시보증공사.csv > sales.csv첫 줄 없애기
pandas에서 전처리하는 방법
df.to_csv('sales.csv',encoding='utf-8',index='False',header='False')csv 파일 hadoop에 저장
[root@localhost ~]# hadoop fs -mkdir -p /user/root/hadoop_edu/sales
[root@localhost ~]# hadoop fs -put sales.csv /user/root/hadoop_edu/sales테이블 생성
hive> create external table hadoop_edu.sales
> (
> region STRING,
> typedata STRING,
> yeardata STRING,
> monthdata STRING,
> price INT
> )
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ','
> LINES TERMINATED BY '\n'
> LOCATION '/user/root/hadoop_edu/sales';테이블 따로 생성하고 데이터 넣는 방법
load data inpath 'hadoop_edu/sales' into table sales;쿼리 실행

지역별 평균 구하기
hive> set hive.exec.reducers.bytes.per.reducer=1073741824;
hive> set hive.exec.reducers.max=32;
hive> set mapreduce.job.reduces=10;
select sales.region, avg(sales.price) from hadoop_edu.sales group by sales.region;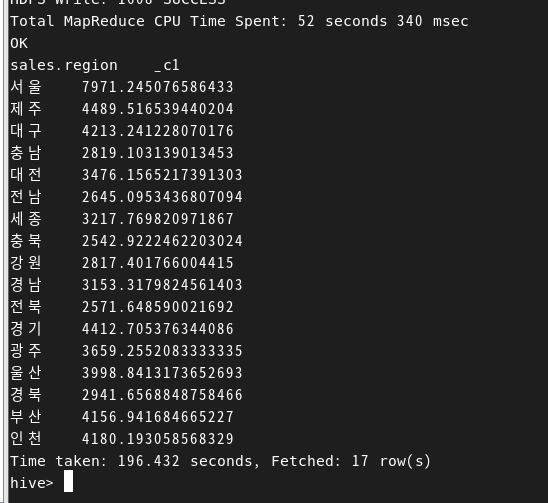
내림차순으로 정렬

연도별 평균 구하기
hive> select sales.year, avg(sales.price) avg_price from hadoop_edu.sales
group by sales.year order by avg_price desc;
서브쿼리
hive> select T.region, avg(T.price) from
> (select * from sales limit 10) as T
> group by T.region;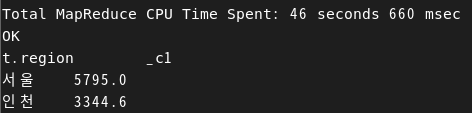
데이터 전처리
면적에 대한 행 이름바꾸기
strdata = df.iloc[:,1].value_counts().index
strdata2 = ['all','60under','60-85','85-102','102over']
df[5] = df.iloc[:,1].map(dict(zip(strdata,strdata2)))
df = df.drop(columns=[1])
df = df.loc[ :, [0,5,3,4,2] ]
df.to_csv("test3.csv",encoding='utf-8',index=False,header=False)
pd.read_csv("test3.csv",header=None)
linux 환경으로 옮기기
C:\Users\Playdata>scp C:\Users\Playdata\Downloads\encoded_sales.csv root@192.168.111.100:/root[root@localhost ~]# hadoop fs -mkdir -p /user/root/hadoop_edu/encoded_sales
[root@localhost ~]# hadoop fs -put encoded_sales.csv /user/root/hadoop_edu/encoded_saleshive> create table aptprice (region string, aptsize string, aptmonth string, aptprice int)
> partitioned by (aptyear string)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ','
> LINES TERMINATED BY '\n'
> LOCATION '/user/root/hadoop_edu/encoded_sales';partiton을 사용해서 테이블 생성하고 쿼리 돌리니까 굉장히 빨라졌다.
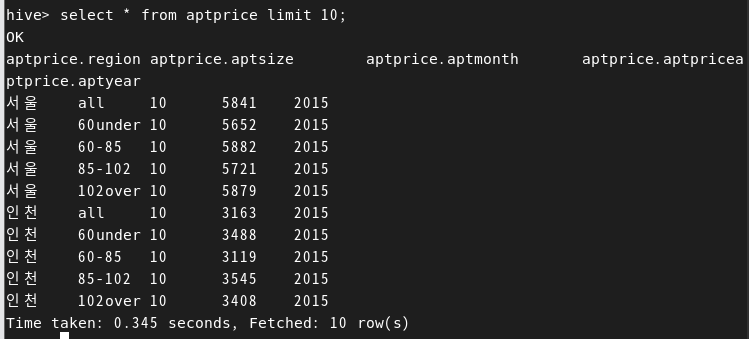
ORC로 하면 더 빨라짐
ORC파일 : raw 포멧의 데이터를 줄이는 기법
기존 raw데이터를 포함한 테이블을
ORC타입으로 저장하는 새로운 테이블로 복사해서 사용
CREATE TABLE aptprice_orc
STORED AS ORC tblproperties("compress.mode"="SNAPPY")
AS
select * from aptprice
;
'Data Engineering > Hive' 카테고리의 다른 글
| [Hive] Hive 서비스 (2) | 2024.03.08 |
|---|---|
| [Hive] Hive 실습 (1) | 2024.03.08 |
| [Hive] Hive 설치하기 (0) | 2024.03.08 |


