https://github.com/RobinDong/hive-examples/blob/master/employee/employees.csv.gz
https://github.com/RobinDong/hive-examples/blob/master/employee/salaries.csv.gz
사이트에서 employees, salaries 내려받아 압축 풀기
employees.csv, salaries.csv 에서 따옴표 공백으로 대체하기
vi 에디터에서 :%s/'//g

HDFS에 데이터 저장
1. 데이터를 저장한 디렉토리 생성
[root@localhost ~]# hadoop fs -mkdir -p /user/root/hadoop_edu/employees
[root@localhost ~]# hadoop fs -mkdir -p /user/root/hadoop_edu/salaries2. 하둡에 데이터 저장
[root@localhost ~]# hadoop fs -put employees.csv /user/root/hadoop_edu/employees
[root@localhost ~]# hadoop fs -put salaries.csv /user/root/hadoop_edu/salaries3. 데이터 저장 상태 확인
[root@localhost ~]# hadoop fs -ls -R /user/root/hadoop_edu
drwxr-xr-x - root supergroup 0 2024-03-08 11:37 /user/root/hadoop_edu/employees
-rw-r--r-- 1 root supergroup 13821993 2024-03-08 11:37 /user/root/hadoop_edu/employees/employees.csv
drwxr-xr-x - root supergroup 0 2024-03-08 11:38 /user/root/hadoop_edu/salaries
-rw-r--r-- 1 root supergroup 97932033 2024-03-08 11:38 /user/root/hadoop_edu/salaries/salaries.csv.bashrc 수정
# hive path
export HIVE_HOME=/root/apache-hive
export PATH=$HIVE_HOME/bin:$PATHjdk1.8 설치 후 재설정
jdk 경로를 bashrc와 hadoop-env.sh 파일에서 수정해 주었다.
만약 가상머신을 끄고 다시 실행한다면, dfs와 yarn을 start-all을 이용하여 다시 실행하고 메타스토어를 초기화해야 함
메타스토어 초기화
[root@localhost apache-hive]# bin/schematool -initSchema -dbType derby메타스토어 초기화해도 hive 접속 시 sql이 작동 안하는 경우가 종종 생김
-> apache-hive 폴더 밑에서 hive 실행하면 잘 된다 ... 왜지
테이블 생성
employee 테이블
CREATE DATABASE IF NOT EXISTS hadoop_edu;
CREATE EXTERNAL TABLE hadoop_edu.employee
(
employee_id INT,
birthday DATE,
first_name STRING,
family_name STRING,
gender CHAR(1),
work_day DATE
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS textfile
LOCATION '/user/root/hadoop_edu/employees'
;salary 테이블
CREATE DATABASE IF NOT EXISTS hadoop_edu;
CREATE EXTERNAL TABLE hadoop_edu.salary
(
employee_id INT,
salary INT,
start_date DATE,
end_day DATE
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS textfile
LOCATION '/user/root/hadoop_edu/salaries'
;쿼리 테스트
use hadoop_edu;select * from employee limit 10;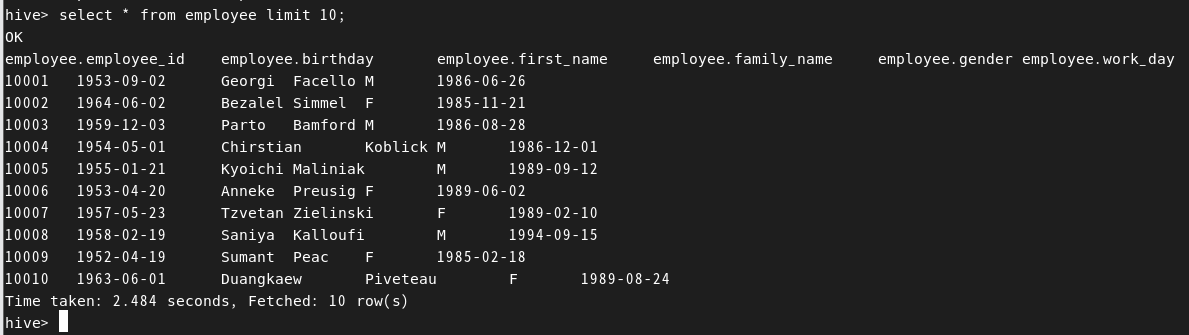
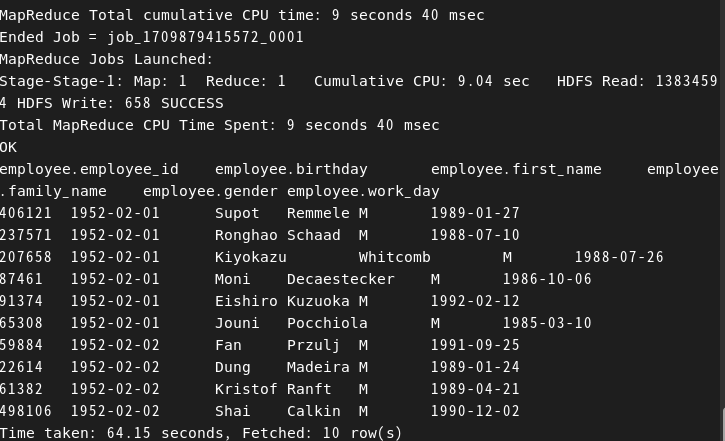
꼰대일 확률이 높은 10명 찾기
select * from employee order by birthday limit 10;order by 가 실행이 안되서 해결한 방법 : 가상환경의 메모리 문제라고 판단하여 용량을 4gb로 늘리고 다시 실행
90년 1월 입사자 10명 찾기
SELECT *
FROM hadoop_edu.employee
WHERE work_day >= '1990-01-01' and work_day <= '1990-01-31' LIMIT 10;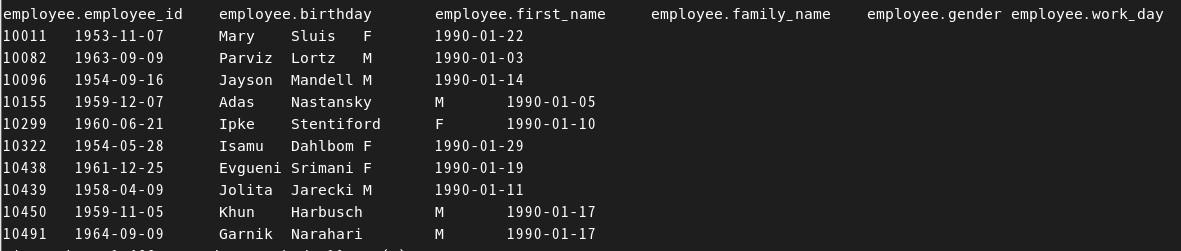
성별 평균 연봉 구하기
SELECT e.gender, AVG(s.salary) AS avg_salary
FROM employee AS e JOIN salary AS s ON (e.employee_id = = s.employee_id)
GROUP BY e.gender;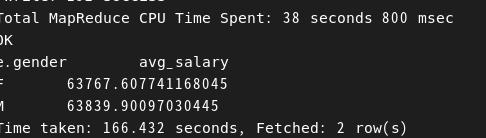
연봉 Top 100 리스트 추출 후 테이블로 저장
CREATE TABLE IF NOT EXISTS hadoop_edu.top_100_salary_employee
(
employee_id INT,
first_name STRING,
family_name STRING,
avg_salary DOUBLE
)
PARTITIONED BY (gender string)
STORED AS ORC
LOCATION '/user/root/hadoop_edu/top_100_salary_employee';INSERT OVERWRITE TABLE hadoop_edu.top_100_salary_employee PARTITION (gender)
SELECT e.employee_id, e.first_name, e.family_name, avg(s.salary) as avg_salary, e.gender
FROM hadoop_edu.employee as e join hadoop_edu.salary as s on (e.employee_id == s.employee_id)
GROUP BY e.employee_id, e.first_name, e.family_name, e.gender
ORDER BY avg_salary
LIMIT 100;연봉 Top 100 리스트 추출 후 테이블로 저장된 데이터 확인
SELECT gender, count(*) cnt
FROM hadoop_edu.top_100_salary_employee
GROUP BY gender;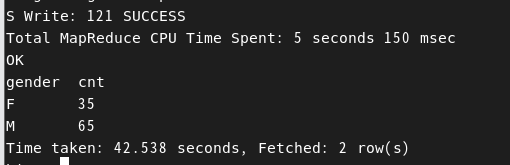

'Data Engineering > Hive' 카테고리의 다른 글
| [Hive] 공공데이터 활용하기 (0) | 2024.03.11 |
|---|---|
| [Hive] Hive 서비스 (2) | 2024.03.08 |
| [Hive] Hive 설치하기 (0) | 2024.03.08 |


