SGRAN
이미지의 화질을 개선하기 위한 GAN 모델의 일종
일반적인 GAN에는 없는 특징 추출기가 있어, 생성자가 감별자를 속임과 동시에, 진짜 이미지와 비슷한 특징을 갖도록 학습됨
- GAN 손실 : 감별자를 속이기 위한 손실
- 콘텐츠 손실 : 생성자가 더 자연스러운 이미지를 생성하기 위한 손실
학습 과정
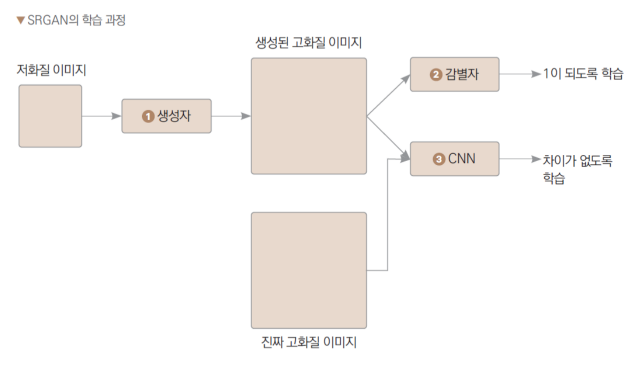
학습용 데이터셋 만들기
사용하는 데이터셋
https://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
!unzip '/content/drive/MyDrive/Colab Notebooks/PLAYDATA_수업/img_align_celeba.zip' -d GAN평균, 표준편차 구하기
imgs = glob.glob("./GAN/img_align_celeba/*.jpg")
import numpy as np
img_data = np.array(Image.open(imgs[0]))
img_data[:,:,0].reshape(-1)
mean_img = np.mean(img_data[:,:,0]) /255,np.mean(img_data[:,:,1]) /255,np.mean(img_data[:,:,2]) /255
std_img = np.std(img_data[:,:,0]) /255,np.std(img_data[:,:,1]) /255,np.std(img_data[:,:,2]) /255각 채널(RGB)에 대한 픽셀 값의 평균을 계산하고, 이를 255로 나누어 [0, 1] 범위로 정규화
import glob
import torchvision.transforms as tf
from torch.utils.data import Dataset
from PIL import Image
class CelebA(Dataset):
def __init__(self):
# glob : 지정된 패턴과 일치하는 모든 파일의 리스트를 반환
self.imgs = glob.glob('/content/GAN/img_align_celeba/*.jpg')
# 입력용 이미지
self.low_res_tf = tf.Compose([
tf.Resize((32,32)), # 이미지 크기를 (32, 32)로 조정
tf.ToTensor(), # 이미지를 텐서로 변환합니다. (딥러닝 모델에서는 이미지 데이터를 텐서 형식으로 사용합니다.)
tf.Normalize(mean_img, std_img) # 이미지의 평균과 표준편차를 주어진 값으로 정규화
])
# 정답용 이미지
self.high_res_tf = tf.Compose([
tf.Resize((64,64)),
tf.ToTensor(),
tf.Normalize(mean_img, std_img)
])
def __len__(self):
return len(self.imgs)
def __getitem__(self, i):
img = Image.open(self.imgs[i])
# 저화질 이미지는 입력으로
img_low_res = self.low_res_tf(img)
# 고화질 이미지는 정답으로
img_high_res = self.high_res_tf(img)
return [img_low_res, img_high_res]저화질을 받아 고화질로 나타내기 위해 입력은 (32,32), 출력은 (128,128) 크기로 리사이징 한다.
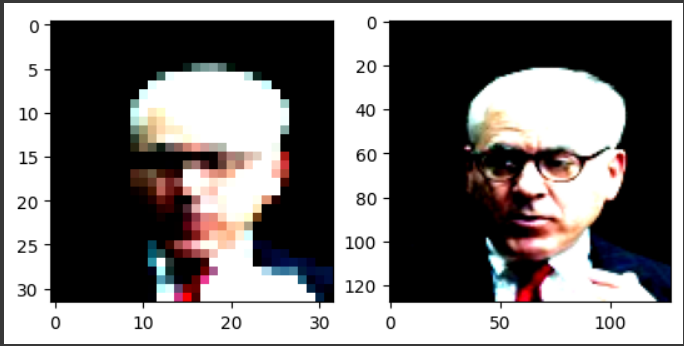
입력 데이터 검증
# 검증
import matplotlib.pyplot as plt
dataset = CelebA();
low_img, high_img = next(iter(dataset))
plt.subplot(1,2,1)
# 차수 순서 바꿔줘야함
plt.imshow(low_img.permute(1,2,0))
plt.subplot(1,2,2)
plt.imshow(high_img.permute(1,2,0))
plt.show()next(iter(dataset))
dataset을 반복 가능한(iterable) 객체로 만들고, next 함수를 사용하여 첫 번째 데이터 쌍을 가져온다.
__iter__ 혹은 __getitem__ 메서드를 구현하여 데이터를 가져오는 방법을 지정하면 next 함수를 사용하여 반복할 수 있다.
permute(1,2,0)
PyTorch에서 이미지의 차원 순서는 일반적으로 (채널, 높이, 너비)이다.
그러나 Matplotlib에서 이미지를 표시할 때는 일반적으로 (높이, 너비, 채널) 순서를 사용하기 때문에 이미지의 차원 순서를 변경해야 한다.
생성자 정의하기
기본 블록
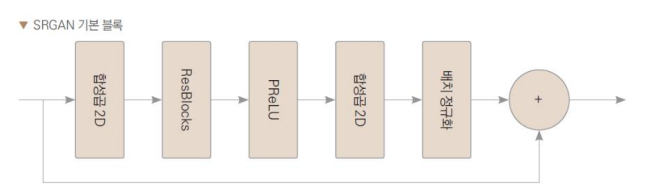
import torch.nn as nn
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels):
# 파이썬의 클래스 상속 구문에서 사용되는 부모 클래스의 생성자를 호출하는 메서드
super(ResidualBlock, self).__init__()
# 생성자의 구성요소 정의
self.layers = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_channels),
nn.PReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
x_ = x
x = self.layers(x)
# 합성곱층을 거친 후 원래의 입력 텐서와 더해줌
x = x_ + x
return xLeekyReLU : 0 이하의 값에서 기울기 고정
PReLU : 0 이하의 값에서 기울기 학습 가능
합성곱 층 채널 변화 확인해보기
# (1,3,128,128)
# 채널 3개로 들어가서 out_channel인 64로 바뀜
import torch
temp_layer = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
temp_data = torch.Tensor(range(1*3*128*128)).reshape(1,3,128,128)
temp_layer(temp_data).shape
업샘플링층
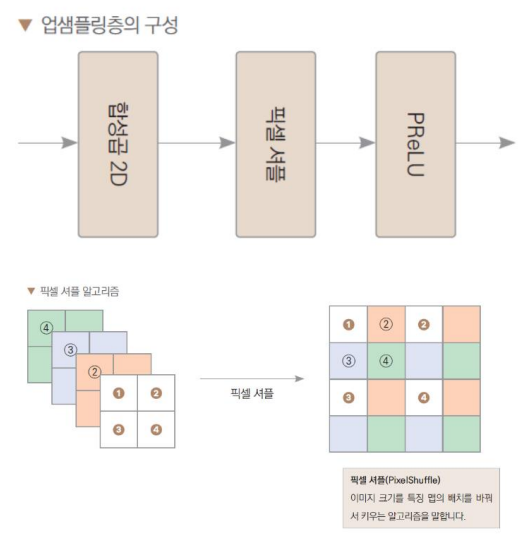
픽셀 셔플 : 이미지 크기를 특징 맵의 배치를 바꿔서 키우는 알고리즘
class UpSample(nn.Sequential):
def __init__(self, in_channels, out_channels):
super(UpSample, self).__init__(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1),
nn.PixelShuffle(upscale_factor=2),
nn.PReLU()
)temp_layer = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
temp_data = torch.Tensor(range(1*3*32*32)).reshape(1,3,32,32)
temp_upsample = UpSample(3,64)
temp_upsample(temp_data).shape
입력 데이터 (1,3,32,32) -> 출력 데이터 (1,16,64,64)
upscale_factor=2 이기 때문에 두배로 커진 것을 확인 할 수 있다.
생성자 정의
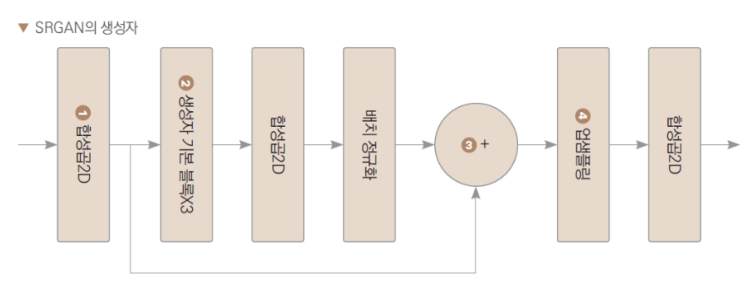
활성화 함수 안거치는 이유 : 이미지를 개선하기 위해 픽셀 값들이 중요하기 때문
합성곱 층의 결과를 그대로 사용한다
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# 첫 번째 합성곱층
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=9, stride=1, padding=4),
nn.PReLU()
)
# 합성곱 블록
self.res_blocks = nn.Sequential(
ResidualBlock(in_channels=64, out_channels=64),
ResidualBlock(in_channels=64, out_channels=64),
ResidualBlock(in_channels=64, out_channels=64)
)
self.conv2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(64)
# 업샘플링층
self.upsample_blocks = nn.Sequential(
UpSample(64,256)
)
# 마지막 합성곱층
self.conv3 = nn.Conv2d(64, 3, kernel_size=9, stride=1, padding=4)
def forward(self, x):
# 첫 번째 합성곱층
x = self.conv1(x)
# 합성곱 블록을 거친 결과와 더하기 위해 값 저장
x_ = x
# 합성곱 블록
x = self.res_blocks(x)
x = self.conv2(x)
x = self.bn2(x)
# 합성곱 블록과 첫 번째 합성곱층의 결과를 더함
x = x + x_
# 업샘플링 블록
x = self.upsample_blocks(x)
# 마지막 합성곱층
x = self.conv3(x)
return x감별자 정의하기
기본 블록
class DiscBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super(DiscBlock, self).__init__()
self.layers = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU()
)
def forward(self, x):
return self.layers(x)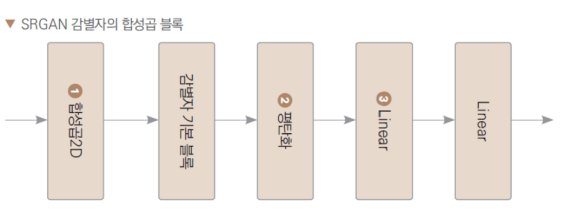
감별자 정의
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3,64,kernel_size=3,stride=1,padding=1),
nn.LeakyReLU()
)
self.blocks = DiscBlock(64,64)
# 평탄화
self.fc1 = nn.Linear(64*32*32,1024)
self.activation = nn.LeakyReLU()
self.fc2 = nn.Linear(1024,1)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
# 합성곱층
x = self.conv1(x)
x = self.blocks(x)
# 1차원으로 펼쳐줌
x = torch.flatten(x, start_dim=1)
# 이진분류 단계
x = self.fc1(x)
x = self.activation(x)
x = self.fc2(x)
x = self.sigmoid(x)
return x검증
temp_model = Discriminator()
temp_g = Generator()
# 저화질 32,32를 생성자에 입력해서 나온 이미지를 감별자에 넣는다.
# (1,3,32,32)
temp_tensor = torch.Tensor(np.array(range(1*3*32*32)).reshape(1,3,32,32))
temp_tensor.shape
gen = temp_g(temp_tensor)
print(gen.shape)
dis = temp_model(gen)
print(dis.shape)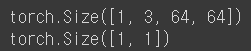
CNN 특징 추출기 정의
고해상도 이미지와 생성된 고해상도 이미지 사이의 차이를 계산하기 위해 사용
이 클래스는 사전 훈련된 VGG19 모델을 기반으로하여 고해상도 이미지에서 특징을 추출하는 역할을 한다.
import torch
from torchvision.models.vgg import vgg19
class FeatureExtractor(nn.Module):
def __init__(self):
super(FeatureExtractor, self).__init__()
vgg19_model = vgg19(pretrained=True)
# vgg19의 9개 층만 이용
self.feature_extractor = nn.Sequential(
*list(vgg19_model.features.children())[:9])
def forward(self, img):
return self.feature_extractor(img)검증
temp_model = FeatureExtractor()
temp_tensor = torch.Tensor(np.array(range(1*3*32*32)).reshape(1,3,32,32))
temp_model(temp_tensor).shape
모델 학습하기
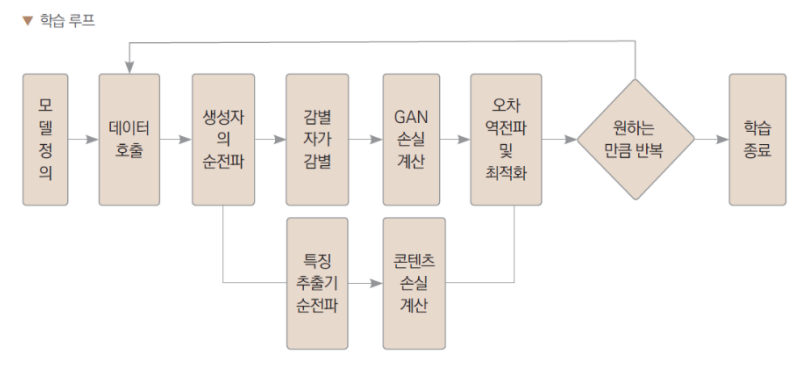
import tqdm
from torch.utils.data.dataloader import DataLoader
from torch.optim.adam import Adam
device = "cuda" if torch.cuda.is_available() else "cpu"
# 데이터로더 정의
dataset = CelebA()
batch_size = 8
loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)- device 변수를 설정하여 GPU를 사용할 수 있는 경우 "cuda"로 설정하고, 그렇지 않으면 "cpu"로 설정 -> 모델을 GPU 또는 CPU에 올리기 위한 목적
- DataLoader는 데이터셋을 미니배치로 나누어서 제공하며, 이를 통해 효율적인 학습을 가능하게 함
- shuffle=True : 데이터를 무작위로 섞음
# 생성자와 감별자 정의
G = Generator().to(device)
D = Discriminator().to(device)
feature_extractor = FeatureExtractor().to(device)
feature_extractor.eval()
# 생성자와 감별자의 최적화 정의
G_optim = Adam(G.parameters(), lr=0.0001, betas=(0.5,0.999))
D_optim = Adam(D.parameters(), lr=0.0001, betas=(0.5,0.999))to(device) : device에 맞게 GPU 또는 CPU로 이동시켜 모델이 GPU에서 실행되도록 한다.
G_optim = Adam(G.parameters(), lr=0.0001, betas=(0.5,0.999)): 생성자 모델의 파라미터를 최적화하는 Adam 옵티마이저를 정의, 학습률(learning rate)은 0.0001로 설정되며, Adam 옵티마이저의 하이퍼파라미터인 betas는 (0.5, 0.999)로 설정
D_optim = Adam(D.parameters(), lr=0.0001, betas=(0.5,0.999)): 감별자 모델의 파라미터를 최적화하는 Adam 옵티마이저를 정의
for epoch in range(1):
iterator = tqdm.tqdm(loader)
for low_res, high_res in iterator:
# 기울기 초기화 : 이전 반복에서 계산된 기울기 초기화
G_optim.zero_grad()
D_optim.zero_grad()
# 진짜 이미지와 가짜 이미지의 정답
label_true = torch.ones(batch_size, dtype=torch.float32).to(device)
label_false = torch.zeros(batch_size, dtype=torch.float32).to(device)
# 생성자 학습
fake_hr = G(low_res.to(device))
GAN_loss = nn.MSELoss()(D(fake_hr), label_true)
# CNN 특징 추출기로부터 추출된 특징 비교
# 가짜 이미지의 특징 추출
fake_features = feature_extractor(fake_hr)
# 진짜 이미지의 특징 추출
real_features = feature_extractor(high_res.to(device))
# 둘의 차이 비교
content_loss = nn.L1Loss()(fake_features,real_features)
# 생성자의 손실
# GAN_loss의 계수가 작을수록 이미지 왜곡은 없지만 해상도는 낮아지고
# GAN_loss의 계수가 클수록 해상도는 높아지지만 이미지 왜곡
loss_G = content_loss + 0.001*GAN_loss
loss_G.backward()
G_optim.step()
# 감별자 학습
# 진짜 이미지의 손실
real_loss = nn.MSELoss()(D(high_res.to(device)), label_true)
# 가짜 이미지의 손실
fake_loss = nn.MSELoss()(D(fake_hr.detach()), label_false)
# 두 손실의 평균값을 최종 오차로 설정
loss_D = (real_loss + fake_loss) / 2
# 오차 역전파
loss_D.backward()
D_optim.step()
iterator.set_description(f"epoch:{epoch} G_loss:{GAN_loss} D_loss:{loss_D}")
torch.save(G.state_dict(),"SRGAN_G.pth")
torch.save(D.state_dict(),"SRGAN_D.pth")- 생성자와 감별자의 기울기를 초기화 : 이전 반복에서 계산된 기울기를 제거하기 위한 작업
- 실제 이미지와 가짜 이미지에 대한 레이블을 정의
- 실제 이미지에 대한 레이블은 1이고, 가짜 이미지에 대한 레이블은 0
- 생성자를 학습 생성자가 생성한 가짜 고해상도 이미지를 만듦
- 생성자의 손실은 두 부분으로 구성
- 첫 번째는 감별자가 가짜 이미지를 실제 이미지로 잘못 분류하는 오차로서, 이를 GAN 손실로 계산
- 두 번째는 생성된 가짜 이미지와 실제 고해상도 이미지 사이의 내용 차이로서, 이를 컨텐츠 손실로 계산
- 감별자를 학습
- 감별자가 실제 이미지를 실제로 인식하고 가짜 이미지를 가짜로 인식하도록 학습
- 감별자의 손실은 실제 이미지와 가짜 이미지의 분류 오차의 평균
- 각 반복에서 생성자와 감별자의 손실을 출력
- 학습이 끝나면 생성자와 감별자의 상태를 파일로 저장
L1, L2 손실
L1 손실 : 정답과 예측값의 차이의 절댓값
L2 손실 : 정답과 예측값의 차이의 제곱
- 1보다 큰 오차를 확대하고 1보다 작은 오차는 줄여주는 효과
L1 규제 : 손실 함수에 가중치 크기를 더해 주는 기법, 불필요한 가중치 제거
L2 규제 : 손실 함수에 가중치 크기의 제곱을 더해주는 기법, 오버피팅 피하기 위해 사용
여기서는 L2 손실을 이용하면 오차가 줄어들게 되므로 L1 손실 이용
'ML,DL' 카테고리의 다른 글
| [DL] 인공 신경망 - 심층 신경망(렐루 함수, Flatten) (0) | 2024.04.16 |
|---|---|
| [DL] 인공 신경망 - 단일 신경망 (0) | 2024.04.16 |
| [ML] 트리의 앙상블 (1) | 2024.04.12 |
| [ML] 확률적 경사 하강법 (0) | 2024.04.08 |
| [ML] 로지스틱 회귀 Logistic Regression (0) | 2024.04.08 |



