1. Producer 생성
Kafka 라이브러리 설치
# 카프카 라이브러리 설치
!pip install kafka-pythonTopic이 읽을 파일 생성
1부터 1000까지 숫자들이 들어있는 파일을 생성한다.
# 토픽이 읽을 파일을 생성
with open('new-topic.txt', 'w') as f:
for i in range(1,1001):
f.write(str(i) + '\n')Producer 생성
# 프로듀서 생성(토픽으로 데이터를 전송)
from kafka import KafkaProducer
import json
import time
from csv import reader
class MessageProducer:
def __init__(self,broker,topic):
self.broker = broker
self.topic = topic
params = {
'bootstrap_servers' : self.broker,
'value_serializer' : lambda x : json.dumps(x).encode('utf-8'),
'acks' : 0, # 클라이언트의 응답을 기다리지 않고 다음 메세지 전송(높은 전송속도 보장, 메세지 전송을 보장하지 않을 수 있음)
'api_version' : (2,5,0),
'retries' : 3 # 재전송 횟수
}
self.producer = KafkaProducer(**params)
def send_message(self, msg):
try:
future = self.producer.send(self.topic, msg)
self.producer.flush() # 메세지 버퍼를 비워줌
future.get(timeout=60) # 60초간 대기
return {'status_code':200, 'error':None}
except Exception as e:
print('error:',e)
return eacks 옵션
acks : 1 (default) -> 속도는 보통, 유실가능성 있음
acks : all or -1 -> 속도는 가장 느림, 메세지 전달 손실 가능성은 없음
브로커와 토픽명 지정, 프로듀서 실행
# 브로커와 토픽명을 지정
broker = 'localhost:9092'
topic = 'test'
message_producer = MessageProducer(broker,topic)
with open('new-topic.txt','r',encoding='utf-8') as f:
for data in f:
print('send-data:',data)
res = message_producer.send_message(data)Consumer가 실행되는 창에서 1~1000까지 숫자들이 출력되는 것을 확인할 수 있다.

2. Consumer 생성
# 컨슈머 생성(토픽의 데이터를 소비)
from kafka import KafkaConsumer
import json
import time
from csv import reader
class MessageConsumer:
def __init__(self,broker,topic,group_id):
self.broker = broker
self.topic = topic
self.group_id = group_id
def active_listener(self):
params = {
'bootstrap_servers' : self.broker,
'group_id' : self.group_id,
'consumer_timeout_ms' : 1000 * 5,
# 토픽을 처음 구독할때 또는 컨슈머의 오프셋이
# 브로커에 의해 처음 삭제될 때 시작 오프셋을 설정
'auto_offset_reset' : 'latest',
'enable_auto_commit' : False,
# 역직렬화
# ASCII decoding, JSON parsing
'value_deserializer' : lambda x : json.loads(x.decode('ascii'))
}
consumer = KafkaConsumer(**params);
consumer.subscribe(self.topic) # 구독, 지정한 토픽의 데이터 감지되면 읽는다(소비한다)
# 데이터 출력 - 데이터를 읽었을때 처리할 로직
for data in consumer:
print(data.value)실행
# 브로커와 토픽명을 지정
broker = 'localhost:9092'
topic = 'test'
group_id = 'consumer-1'
consumer = MessageConsumer(broker,topic,group_id)
consumer.active_listener()파일로 출력하기
start_time = time.time()
# 데이터 출력 - 데이터를 읽었을때 처리할 로직
try:
# for data in consumer:
# print(data.value)
with open(f"result_{self.topic}.txt",'a', encoding='utf-8') as f:
for data in consumer:
f.write(data.value)
end_time = time.time()
print(f"총 처리시간 : {end_time - start_time}")
except KeyboardInterrupt:
print("KeyboardInterrupt")result_test.txt에 저장된 것 확인
총 처리시간 확인

3. 3개의 Producer, Consumer 생성하기
Zookeeper, Kafka를 실행하고 Topic p1, p2, p3를 먼저 생성해준다.
Producer
# 프로듀서 3개 생성
broker = 'localhost:9092'
message_producer1 = MessageProducer(broker,"p1")
message_producer2 = MessageProducer(broker,"p2")
message_producer3 = MessageProducer(broker,"p3")
with open('new-topic.txt','r',encoding='utf-8') as f:
for data in f:
message_producer1.send_message(data)
message_producer2.send_message(data)
message_producer3.send_message(data)Consumer
# 브로커와 토픽명을 지정
broker = 'localhost:9092'
group_id = 'consumer-1'
consumer1 = MessageConsumer(broker,"p1",group_id)
consumer2 = MessageConsumer(broker,"p2",group_id)
consumer3 = MessageConsumer(broker,"p3",group_id)
consumer1.active_listener()
consumer2.active_listener()
consumer3.active_listener()

result_p1.txt에만 데이터가 저장되었다.
Consumer 클래스에서 auto_offset_reset을 earlist로 주면 3개의 파일에 데이터가 모두 쌓인다.
auto_offset_reset
- latest : 마지막으로 구독한 다음 메세지 부터 구독한다. (가장 최신)
- earliest : 처음부터 메세지를 구독한다. (가장 오래된)
- none : 구독하고자 하는 topic의 offset 정보가 없으면 exception을 발생한다.
콘솔에서 확인하기
# p1 producer
bin/kafka-console-producer.sh --topic p1 --bootstrap-server localhost:9092
# p1 consumer
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic p1 --from-beginning
# p2 consumer
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic p2 --from-beginning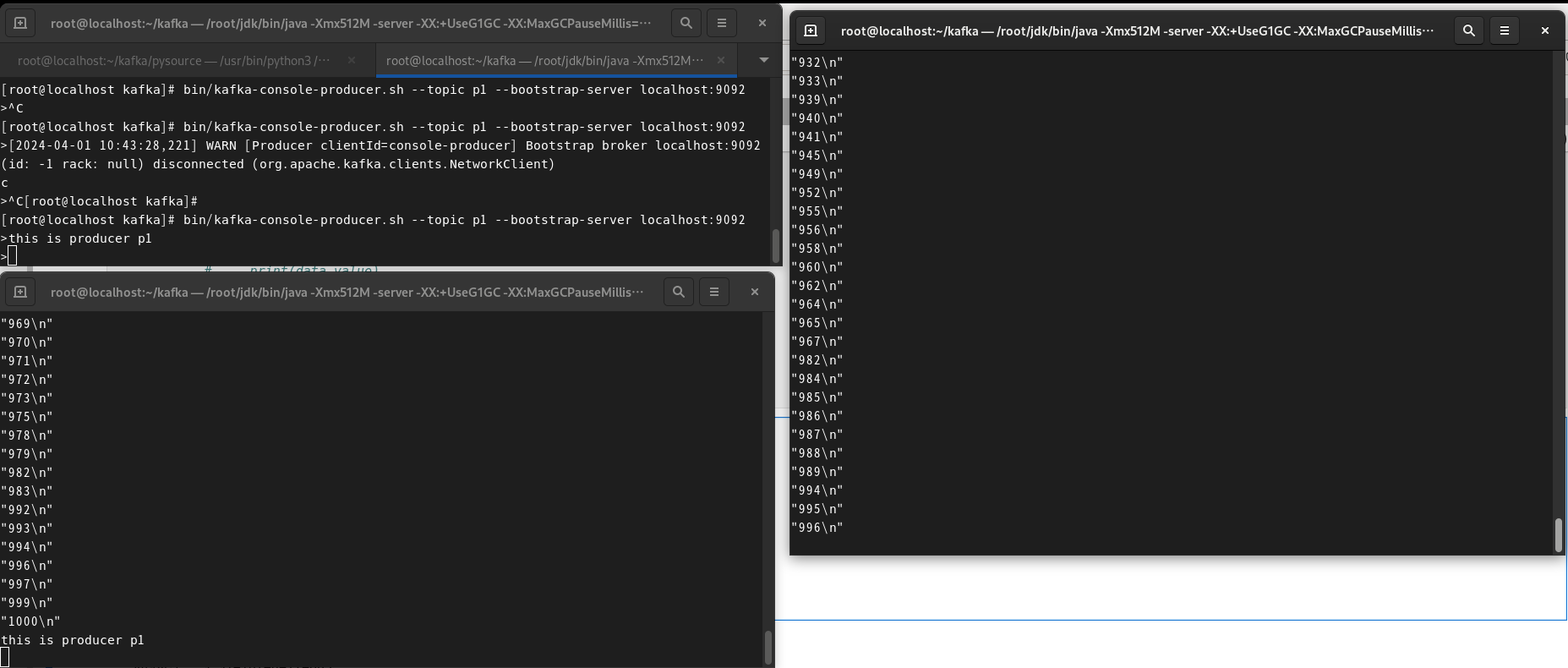
topic을 p1으로 하는 producer를 생성하고, 왼쪽 하단이 p1 consumer, 오른쪽이 p2 consumer이다.
p1 consumer가 'this is producer p1'이라고 메세지를 보내자 p1 consumer만 메세지를 받는 것을 확인할 수 있다.
'Data Engineering > Kafka' 카테고리의 다른 글
| [Kafka] Kafka에서 생성된 데이터를 일정한 시간 단위로 mysql 테이블에 저장하기 (1) | 2024.04.03 |
|---|---|
| [Kafka] json 데이터 처리하기 (1) | 2024.04.01 |
| [Kafka] mysql과 연동하여 Producer, Consumer 실행 (0) | 2024.04.01 |
| [Kafka] Apache Kafka 설치, 서버 실행, Producer, Consumer 생성 (0) | 2024.03.29 |



