https://www.data.go.kr/data/15013094/standard.do
전국CCTV표준데이터
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Datase
www.data.go.kr

<관리기관별>
1. Java로 MapReduce 프로그램 작성
CctvMapper.java
package com.bigdata.cctv;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 맵리듀스에서 데이터를 분리하려면 라인단위로 데이터를 읽어서 \t를 사용해서 데이터를 분리하고 첫번째 인덱스의 데이터를 선택
*/
public class CctvMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable();
private Text word = new Text();
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
String[] strs = value.toString().split("\t");
word.set(strs[0]);
context.write(word,one);
}
}CctvReducer.java
package com.bigdata.cctv;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* 리듀서는 매퍼에서 쓴 데이터가 리스트 형태로 전달됨
* 이 데이터를 모두 더해주면 결과를 확인할 수 있음
*/
public class CctvReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
for(IntWritable value : values) {
sum += value.get();
}
result.set(sum);
context.write(key,result);
}
}CctvMain.java
package com.bigdata.cctv;
//TIP To <b>Run</b> code, press <shortcut actionId="Run"/> or
// click the <icon src="AllIcons.Actions.Execute"/> icon in the gutter.
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* job
* job 함수는 작업에 관련된 정보를 전달, 매퍼, 리듀서, 컴파일러를 설정하고 출력 데이터 타입을 설정
* FileInputFormat에 입력, 출력 정보를 지정
*/
public class CctvMain {
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf,"cctv");
job.setJarByClass(CctvMain.class);
job.setCombinerClass(CctvReducer.class);
job.setMapperClass(CctvMapper.class);
job.setReducerClass(CctvReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}jar로 빌드해서 리눅스에 옮기기
2. Hadoop에서 MapReduce 실행하기
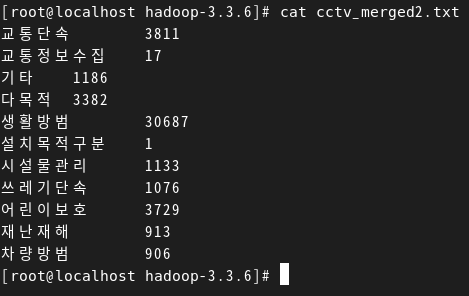
[root@localhost hadoop-3.3.6]# hadoop jar hadoop_mapreduce-1.0-SNAPSHOT.jar com.bigdata.cctv.CctvMain /user/cctv/ /user/cctv/output3. count된 결과 확인

hadoop fs -cat /user/cctv/output/part-r-* > cctv.merged.txt

jupyterlab에서 pandas로 확인해 본 결과와 같다.
<설치목적구분>
위와 비슷하게 진행한다.
CctvMapper.java
package com.bigdata.cctv;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 맵리듀스에서 데이터를 분리하려면 라인단위로 데이터를 읽어서 \t를 이용해서 데이터를 분리하고 첫번째 인덱스의
* 데이터를 선택
*/
public class CctvMapper extends Mapper<Object,Text,Text,IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// 데이터 추출
String[] strs = value.toString().split("\t");
word.set(strs[4]);
context.write(word,one);
}
}Mapper 코드만 살짝 달라졌다. 기존에는 ','를 기준으로 split하였지만 지번주소에 ','를 포함하고 있는 주소들 때문에 문제가 생겨 pyspark에서 csv를 '\t' 기준으로 나눠서 저장되도록 하여 수정했다.
'Data Engineering > Hadoop' 카테고리의 다른 글
| [Hadoop] MapReduce 실행 중 Error: org.apache.hadoop.hdfs.BlockMissingException (0) | 2024.03.27 |
|---|---|
| [Hadoop] Hadoop Streaming (0) | 2024.03.07 |
| [Hadoop] Python으로 MapReduce 구현하기 (0) | 2024.03.07 |
| [Hadoop] Java로 MapReduce 구현하기 (1) | 2024.03.06 |
| [Hadoop] hdfs 명령어 정리 및 실행 (0) | 2024.03.06 |


